Machine Learning: Fundamental Concepts and Algorithms

On this page
The concepts of linear regression, classification, clustering, and Hidden Markov Model (HMM) represent different types of machine learning algorithms or models. These algorithms are designed to address specific types of tasks within the broader field of machine learning.
1. Linear Regression
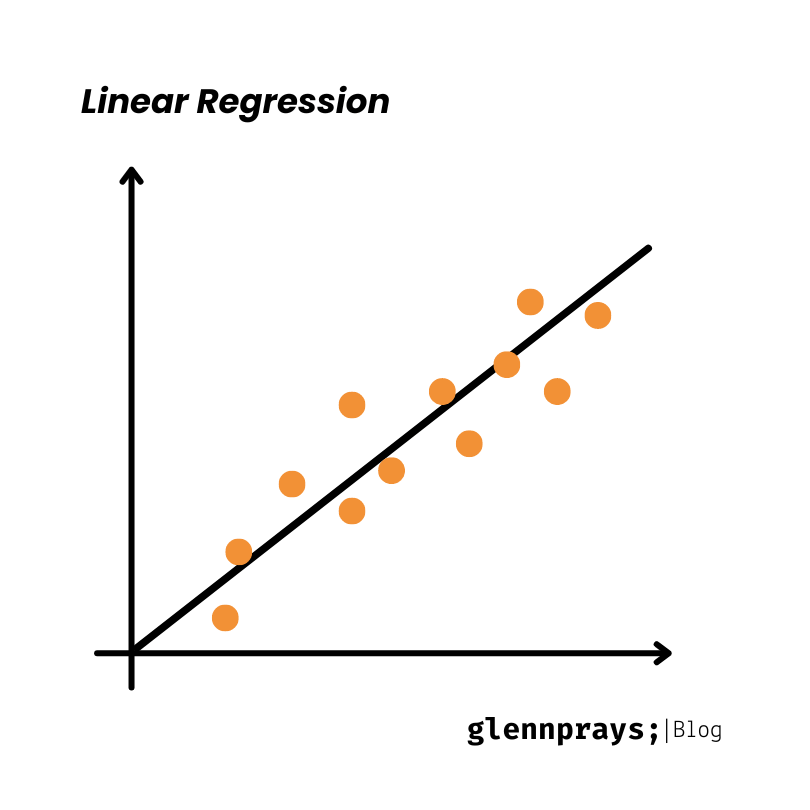 Linear regression, a supervised learning method, predicts a continuous outcome by establishing a presumed linear connection between input features and the target variable.
Linear regression, a supervised learning method, predicts a continuous outcome by establishing a presumed linear connection between input features and the target variable.
The goal is to identify the optimal line (or hyperplane in higher dimensions) that minimizes the discrepancy between predicted and actual values, often achieved through the least squares method.
2. Classification
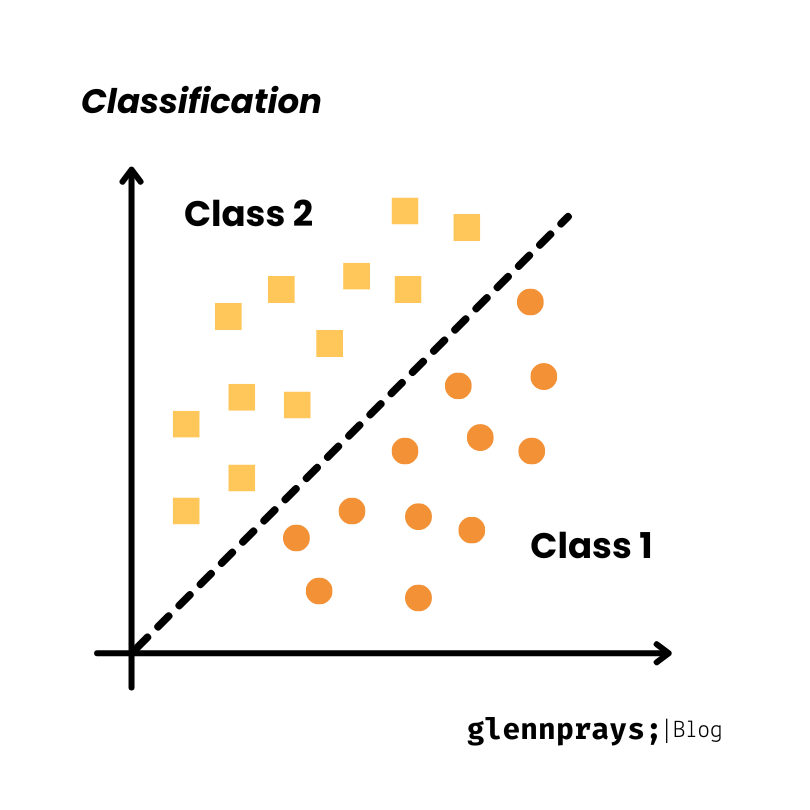 Classification, a type of supervised learning, entails assigning input data points to predefined categories. The process involves training a model to understand the relationship between input features and discrete output labels. Common classification algorithms, such as logistic regression, decision trees, support vector machines, and neural networks, enable the model to discern decision boundaries and classify new data points into specific classes.
Classification, a type of supervised learning, entails assigning input data points to predefined categories. The process involves training a model to understand the relationship between input features and discrete output labels. Common classification algorithms, such as logistic regression, decision trees, support vector machines, and neural networks, enable the model to discern decision boundaries and classify new data points into specific classes.
3. Clustering
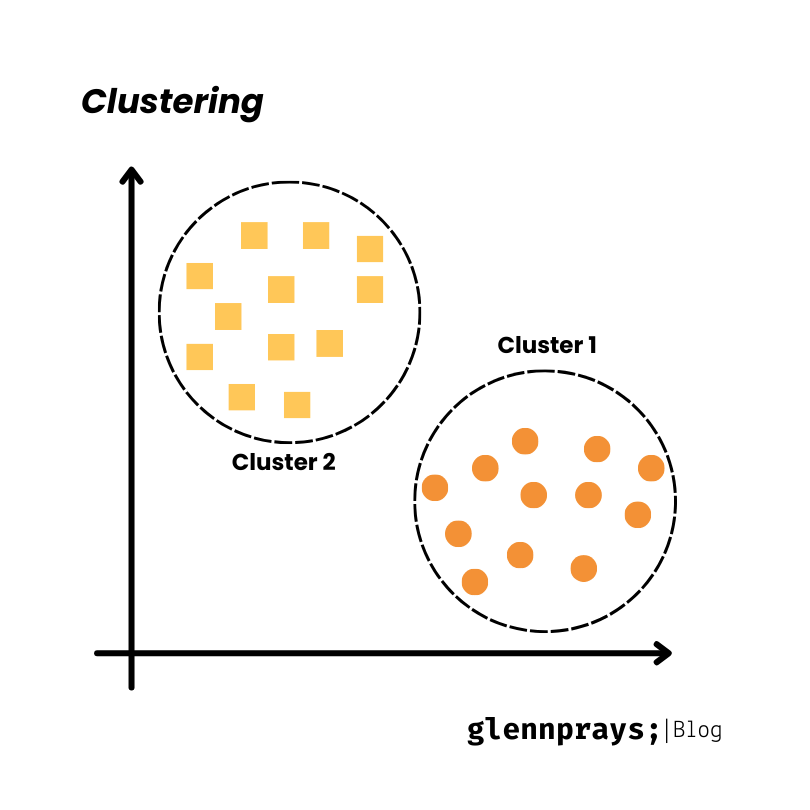 Clustering, an unsupervised learning task, seeks to unite similar data points based on their features, devoid of predefined categories. The aim is to unveil inherent patterns or structures present in the data.
Clustering, an unsupervised learning task, seeks to unite similar data points based on their features, devoid of predefined categories. The aim is to unveil inherent patterns or structures present in the data.
Algorithms for clustering, like K-Means, Hierarchical Clustering, and DBSCAN, organize data into clusters with the goal of maximizing similarity within clusters and minimizing dissimilarity between them.
4. Hidden Markov Model (HMM)
Hidden Markov Model (HMM) serves as a sequential modeling method, employed to represent sequences of observations. It operates under the assumption of an unseen structure evolving over time, where the observed data relies on this concealed underlying pattern.
HMMs have broad utility across various domains like speech recognition, part-of-speech tagging, and bioinformatics. The modeling involves specifying states, transitions, and emissions from each state, adeptly capturing concealed patterns within sequential data.
Conclution
Choose linear regression for predicting continuous outcomes, classification for assigning data to predefined classes, clustering for grouping similar data points, and Hidden Markov Model for modeling sequential data with hidden states. Your decision should align with the characteristics of your data and the specific requirements of your machine learning task.