Machine Learning: Underfitting, Overfitting, and Generalization

On this page
Machine learning models aim for generalization to new data. Underfitting (too simple) and overfitting (too complex) hinder this. Achieving balance ensures effective, robust performance. Imagine you are try to kill a very big monster using fly swatter, it's oversimplified so it is underfitting. In contrast, you are trying to kill a fly using a nuclear bomb, it's overcomplicated so it is overfitting. You need to find a balance between the two. So generalization is when you are able to kill a fly using a fly swatter and kill a monster using a nuclear bomb.
Example of Underfitting and Overfitting
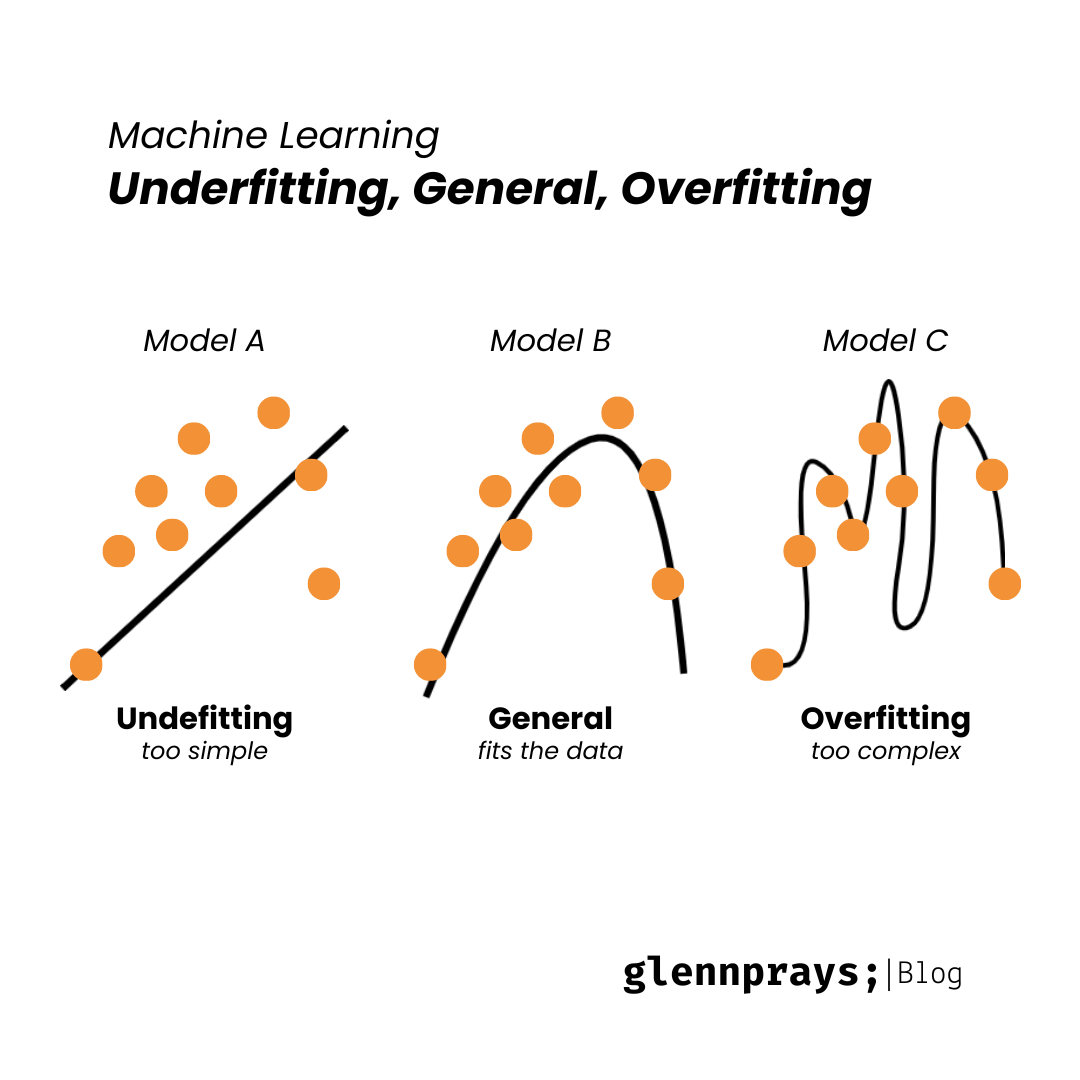 From example above, we can see that the model A on the left is underfitting because it is too simple. The model C on the right is overfitting because it is too complex. The model B in the middle is just right.
From example above, we can see that the model A on the left is underfitting because it is too simple. The model C on the right is overfitting because it is too complex. The model B in the middle is just right.
Prediction results
The goal is to find the best model that neither too simple (underfitting) nor too complex (overfitting). The best model is the one that can generalize well to new data.
- Underfiting: This model has not captured the underlying patterns, so the prediction results are not good. Predictions from an underfit model may be inaccurate and insufficiently nuanced.
- Overfitting: This model memorized the training data, including the noise dan the outliers. So the prediction results leading to poor generalization to new data (unseen data). Overfit models may exhibit erratic behavior, especially when faced with data that differs from the training set.
- Generalization: This model has balance between underfitting and overfitting that will provide accurate prediction results. Predictions from a well-generalized model are reliable and robust across various datasets.
Model Testing
The model that can generalize well to new data is the one that can predict well on the test set. The model that can predict well on the test set is the one that has the lowest test error. The model that has the lowest test error is the one that has the best balance between bias and variance.
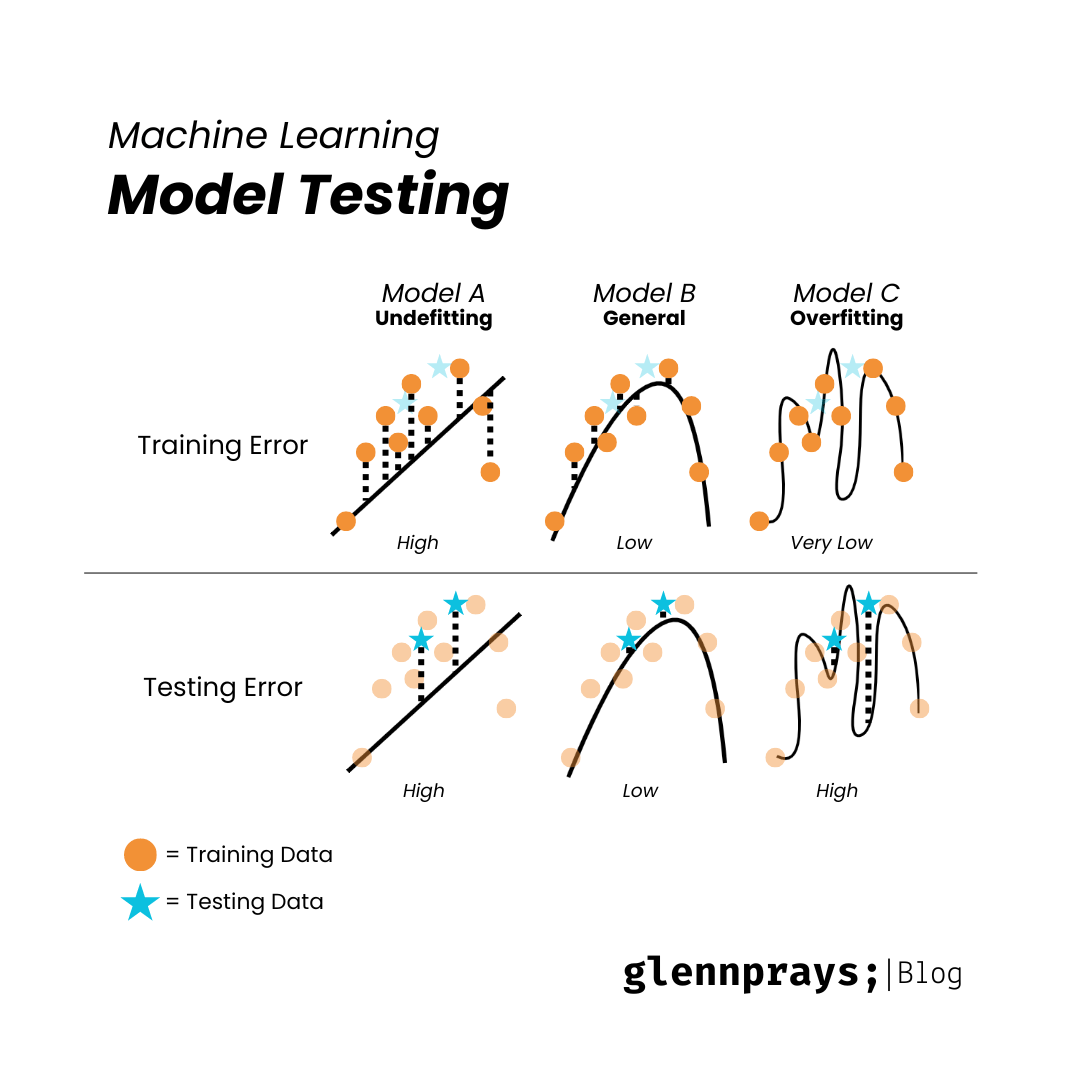 To choose the best fit model, we need to calculate the error function. The error function is the difference between the predicted value and the actual value. The error function is also known as the loss function.
To choose the best fit model, we need to calculate the error function. The error function is the difference between the predicted value and the actual value. The error function is also known as the loss function.
Testing the model is done by splitting the datasets into three parts: training set, validation set, and test set. The training set is used to train the model. The validation set is used to evalute the model during training and make decitions on which model to use. The test set is used to asses the model's performance after training. The common composition to use 60-20-20 or 80-10-10 for training, validation, and test set respectively, in other words, 60% or 80% of the data is used for training, 20% or 10% of the data is used for validation, and 20% or 10% of the data is used for testing.
Conclution
In machine learning, achieving a balance between underfitting and overfitting is crucial for effective model performance. Generalization, represented by a well-balanced model, ensures accurate predictions on both familiar and novel datasets.